# 평가 지표 선택의 중요성
- 검사 모델의 잘못된 예측으로 정확도가 왜곡되어 신뢰성이 낮아질 수 있는 상황이 발생

# Accuracy(정확도)와 Precision(정밀도) 그리고 Recall(재현율)
- 정확도 : 모델과 실제 전체(Positive, Negative) 중에 맞춘(True) 예측
- 정밀도 : 모델의 Positive입장에서 실제 양성의 비율 (ex. 암환자라고 진단된 상태에서 실제 암환자의 비율)
- 재현율 : 실제 양성의 입장에서 모델의 Positive한 비율 (ex. 실제 암환자의 수에서 진단된 암환자의 비율)
- 데이터의 형태에 따라 중요한 평가항목은 다르지만 위 암환자 예시일때는 정밀도가 낮을수록 재현율이 높을수록 낫다.

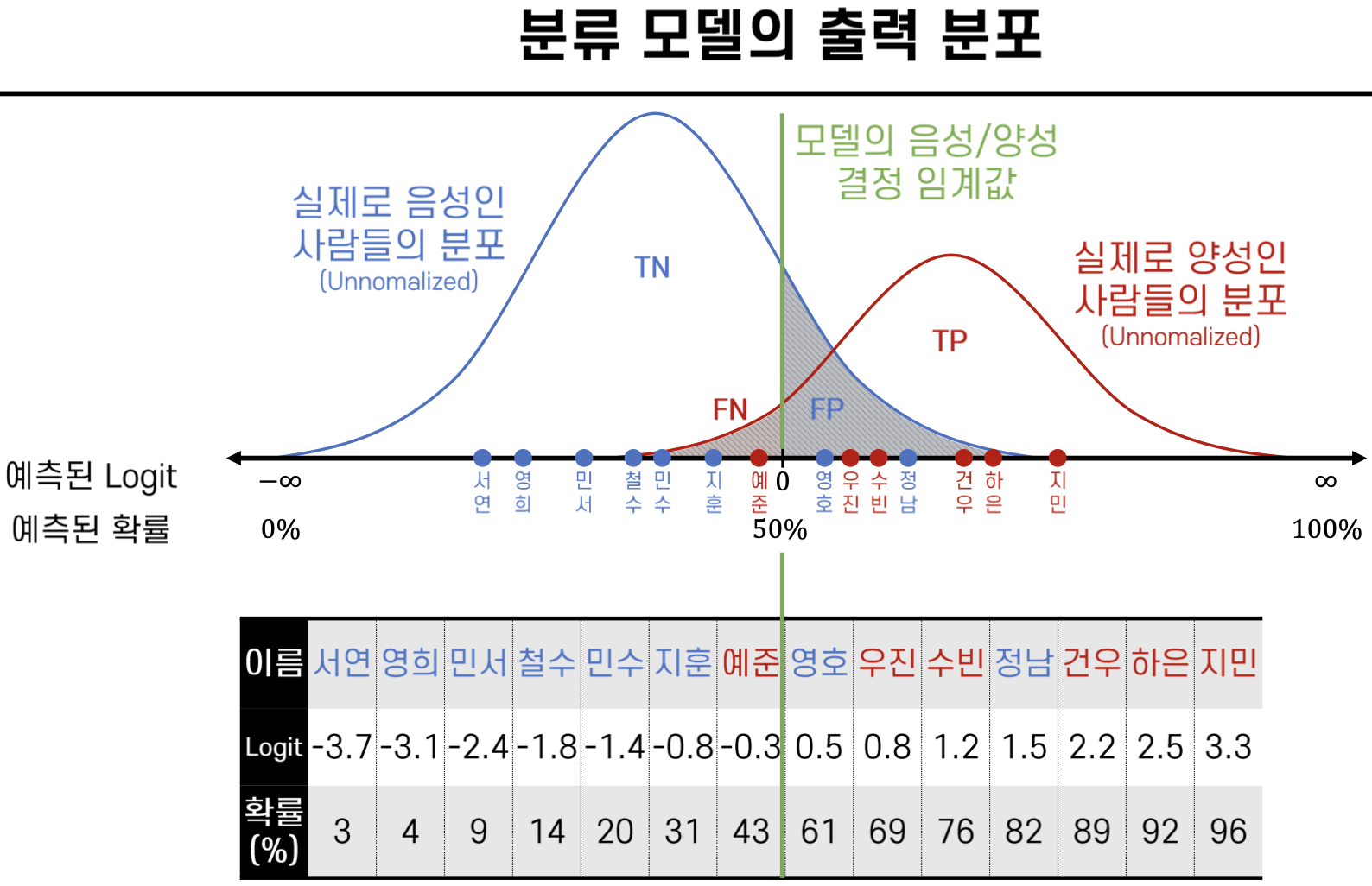
# 분류 모델의 출력 분포
- 모델의 Positive와 Negative를 구분하는 값을 임계값이라하며 0또는 50%로 표기
- 확률이 50%보다 높으면 logit값이 플러스, 낮으면 logit값이 마이너스
# Precision과 Recall간의 관계
- 임계값을 높일수록 양성기준이 엄격해져 FP개수가 작아져 Precision은 높아지며, FN이 커지게되어 Recall은 낮아짐. 임계값이 낮아질때는 반대로 Precision은 낮아지며, Recall은 높아짐.
- 임계값을 임의로 조정하게되면 객관적인 평가가 어렵기에 평가시 우선적으로 임계값을 고정시키거나 다른 평가지표로 사용해야 함.

# 종합 평가 수치: F measure
- F measure는 Precision과 Recall을 같이 포함된 조화평균을 사용하며, Precision과 Recall에 동일 가중치를 가진 F1 measure를 더 많이 사용함.

# 좋은 분류 모델의 조건

# Precision-Recall Curve
- 임계값을 1부터 0까지 순차적으로 좌표를 찾아 그래프를 그린다.



# Receiver Operator Characteristic (ROC) Curve




'yeardreamschool4 > Machine Learing' 카테고리의 다른 글
| #Regularization(정규화) (0) | 2024.05.24 |
|---|---|
| Multi-Class Classification Model (0) | 2024.05.24 |
| Dimension Reduction(차원 축소) (0) | 2024.05.22 |
| Clustering(클러스터링) (0) | 2024.05.22 |
| Logistic Regression(로지스틱 회귀) (0) | 2024.05.20 |



