# 변수(Variable)란?
* 변수는 메모리에 데이터를 저장하기 위한 공간을 가리키는 말이며, 컴퓨터와 프로그래밍 언어 사용자간의 약속이다.
a : 컴퓨터와 사용자가 인식하는 특정 데이터를 저장하고 있는 공간이고, 공간의 이름을 a라고 한다.
* 변수는 일종의 닉네임으로, 실제 물리적인 메모리 주소공간을 가르킨다.
사용자는 변수의 이름으로 데이터를 인식하고, 컴퓨터는 변수의 주소로 데이터를 인식한다.
* 변수에 데이터를 저장할 때는 =를 사용한다. 이 때 =를 assignment operator라고 부른다.
a = 10 (a라는 공간에 10이라는 데이터를 할당한다.)
(OPTIONAL) a = 10을 예로 들었을 때, =을 기준으로 왼쪽을 lvalue라고 하며 실제 메모리 주소를 의미하고, =을 기준으로 오른쪽을 rvalue라고 하며 실제 데이터(또는 값)을 의미한다.

# 숫자 데이터 (Numeric Data Types)
* 숫자형 데이터란, 정수/실수/복소수/2진수/8진수/16진수를 포함하며 가장 많이 사용하는 데이터 타입중에 하나다.
* 파이썬은 숫자의 표현 범위가 무한대이다.
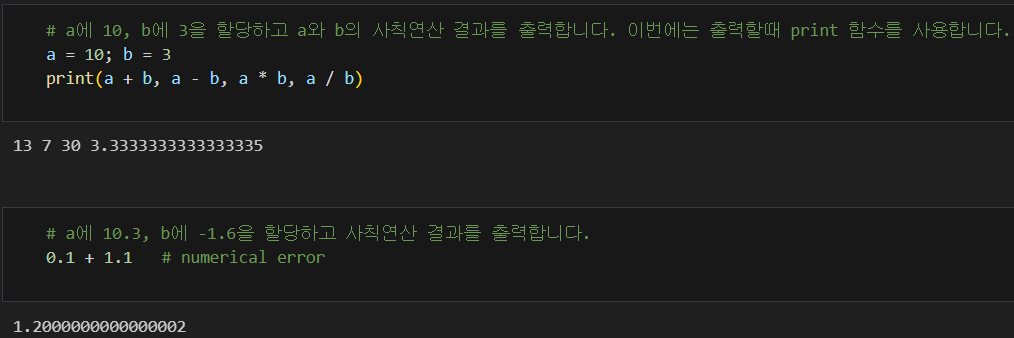
* 숫자 데이터는 우리가 알고 있는 대부분의 연산을 그대로 지원한다. 사칙연산(+-*/), 나머지 구하기(%), 몫 구하기(//), 거듭제곱(**) 등


@ 숫자형 데이터 타입이 제공하는 여러 연산자

# 문자열 (String)
* 문자열 데이터란, 문자(character)의 나열을 의미한다. e.g. "Hello world"
string : Character Sequence
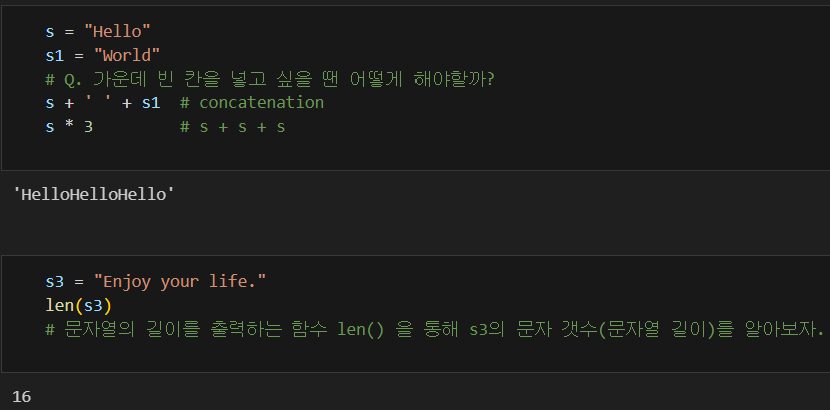
* 파이썬에 다룰 수 있는 문자열의 크기도 제한이 없다.
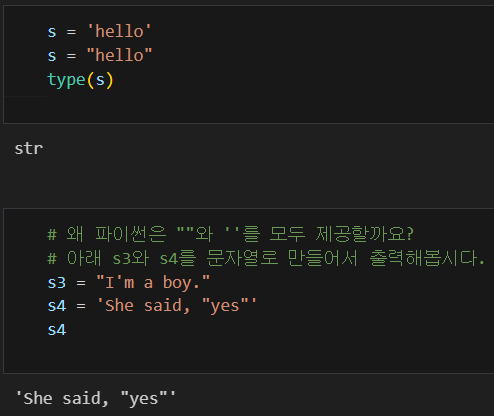
* 파이썬에서 '와 " 두 가지의 기호를 통해 문자열을 나타낸다. 즉, '부터 '까지 또는 "부터 "까지 하나의 문자열이다. e.g. 'Hello', "World"
* 컴퓨터는 문자(character)를 encoding하여 숫자로 표현한다. 알려진 예로 ASCII, utf-8, cp949가 있다.
컴퓨터는 문자를 숫자로 인식한다. e.g. ASCII 코드로 변환하면 A->65, a->97
* 현재 전세계적으로 웹에서 사용되는 국제 표준은 UTF-8(Universal code character Transformation Formatj - 8-bit)이다.
(OPTIONAL) UTF-8에선 a는 1바이트로, '가'는 3바이트로 인식한다. 이를 가변 인코딩 방식이라고 하며, 영어보다 한글이 더 많은 데이터를 필요로 한다.
@ 문자열을 만드는 여러가지 방법
@ 문자열 연산하기
@ 문자열 Formatting
* 문자열을 출력할 때(print 함수를 이용하여) 특정 format을 지정하고 싶은 경우(문자열 포멧)에는 크게 3가지가 있다. (기호에 맞게 사용가능) e.g. OOO님의 주민등록번호는 XXXXXX-XXXXXXX입니다.
"사과는 4개가 있다."
1. print format 사용
print("%s는 %d개 있다." % ("사과", 4))
2. str.format 함수 사용
print("{}는 {}개 있다.".format("사과", 4))
3. f-string (**)
apple = "사과", count = 4
print(f"{apple}는 {count}개 있다.")

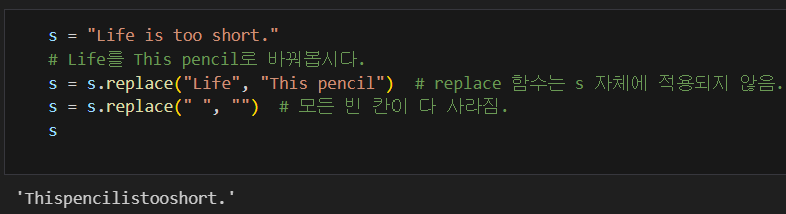
@ 문자열 관련 함수들 (**)

# 연속형 데이터 (Sequential Data Types)
Q. 숫자 100개를 한번에 다루려고 한다. <=> 하나의 변수에 숫자 100개를 저장하고 싶다. 어떻게 해야할까?
A. 연속형 데이터 타입을 사용하자!
* 연속형 데이터란, 하나의 변수가 하나의 데이터를 가지고 있던 숫자형 데이터와 달리, 여러개의 데이터를 하나의 변수에 가지고 있는 데이터 타입이다.
* 연속형 데이터 타입에는 리스트(List), 튜플(Tuple), 문자열(String)이 있다. (문자열을 문자들의 나열로 인식하기 때문에 연속형 데이터이다.)
* 연속성 데이터의 크기 제한은 없다. 하지만, 사용하는 컴퓨터의 가용 메모리 용량을 인지하며 사용해야 한다.
* 각 연속형 데이터 타입마다 특징이 다르다. 그 특징을 파악하여 용도에 맞는 데이터 타입을 사용하는 것이 중요하다.
(OPTIONAL) 사전(dictionary)타입은 associative array라고 불리며, 흔히 알고있는 Hash table 구조이다.
## 리스트(List)
* 가장 많이 사용되는 연속형 데이터 타입이자, 굉장히 유연한 구조를 가지고 있어 대부분의 데이터를 편하게 다룰 수 있다.
* 파이썬에서 [ 와 ] 를 이용하여 표현한다. e.g. [1, 2, 3]
* 리스트의 원소는 쉼표로 구분되며, 리스트의 원소는 아무 데이터 타입이나 가능하다. 리스트조차 가능하다.
* 리스트를 이용하면 파이썬에서 다루는 대부분의 데이터는 아무 무리없이 다룰 수 있다. 하지만 수정이 자유롭기 때문에 수정을 하면 안되는 경우에는 사용하면 안된다.
@ 리스트를 만드는 방법

@ Indexing (***)
* 연속형 데이터들은 하나의 변수에 여러가지 데이터를 가지기 때문에 여러 데이터를 접근하는 방법이 필요하다.
* 이를 위해 indexing이라는 기법이 있다. 말그대로 index를 통해 접근(access)하는 방법이다.
* 리스트의 index는 맨 앞부터 0으로 시작하며, 1씩 증가하는 정수 index를 사용한다.
e.g. [1, 2, 3]이면 첫번째 원소는 index가 0이고, 두번째 원소는 index가 1이다.
* 파이썬에서는 음수 index도 제공하는데, 이는 뒤쪽부터 접근할 수 있는 방법이다.
e.g. [1, 2, 3]이면 뒤에서 첫번째(맨 마지막)원소는 index가 -1이고, 뒤에서 두번째 원소는 index가 -2이다.
* index를 통해 접근하는 방법은 해당 변수이름에 []를 사용하며, []안에 index를 넣어서 접근할 수 있다.
e.g. L = [1, 2, 3]이면 L[0]은 1이고, L[2]는 L[-1]이며 3이다.

@ Slicing (**)
슬라이싱은 리스트에서 뿐만 아니라, 리스트와 비슷한 구조인 numpy array와 pandas series, dataframe에서도 많이 이용되니 꼭 알아두어야 한다.
* 슬라이싱은 리스트의 일부분만 잘라낸다는 의미이다. (말 그대로 슬라이싱)
* 리스트의 일부만 사용하고 싶을 때 쓰는 기법이며, indexing을 범위로 하는 느낌이다.
* 리스트의 index와 : 를 사용하여 슬라이싱을 할 수 있다.
e.g. L = [1, 2, 3, 4] L[0:2]는 [1, 2]이다.

TIP! 문자열도 연속형 데이터 타입이기 때문에, indexing과 slicing이 다 된다.
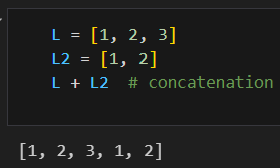
@ 리스트 연산하기


@ 리스트 관련 함수


## 튜플(Tuple)
* tuple은 list와 거의 같다.
indexing, slicing 모두 동일하게 사용 가능하다. 원소들도 자유롭게 사용 가능하다.
* 거의 같은데, 다른 점이 딱 2가지 있다.
1) 리스트는 []를 사용하고, 튜플은 ()을 사용한다.
2) 리스트는 생성 후에 변경이 가능하고(mutable) 튜플은 생성 후에 변경이 불가능하다.(immutable)
mutable : 생성된 이후에 변경(assignment)이 자유롭게 가능한 data type. e.g. List, dict, set
immutable : 생성된 이후에 변경이 불가능한 data type e.g. int, float, string, tuple, frozenset
1. 성능적인 이슈 -> 변경되지는 않는 그 저체로 장점이 생김.
2. 프로그래밍적인 이슈 -> 데이터 수정 자체를 하지 않는 경우 실수를 방지할 수 있다.

## 집합(Set)
* 집합 자료형은 정말 말그대로 수학에서 배우는 집합 그 자체이다.
* 수학에서는 집합을 {}로 표시했지만, 파이썬에서는 안타까운 이유로 {}를 사용하긴 하는데 그냥 사용할 수는 없다. 왜냐면 사전(Dictionary) 자료형도 {}를 사용하기 때문이다. 이에 대해서는 뒤에 자세히 배운다.
* 공집합을 생성할 때는 반드시 set()으로 생성해야 한다. {}로 생성하면 빈 사전이 생성된다.
e.g. {1, 2, 3} : 집합, {'a':1, 'b':2} : 사전
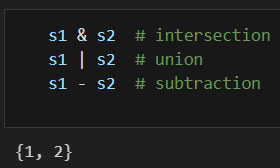
* 집합의 연산자인 교집합, 합집합, 차집합을 모두 지원한다.
* 집합의 특징이 2가지 있는데, 이 특징이 리스트와의 차이점이라 사용한다. 첫번째 특징이 집합 자료형을 사용하는 주된 이유이다.
1. 집합은 원소의 중복을 허용하지 않는다. 즉, 원소의 종류를 나타내기 좋다.
2. 집합은 원소의 순서가 존재하지 않는다. 즉, 원소의 index가 없다.

@ 집합의 연산


# 사전(Dictionary) (**)
파이썬에서 리스트와 함께 굉장히 많이 사용되는 구조. 특히 많이 사용되니 꼭 마스터하는 것을 추천한다.
* 파이썬에서 제공되는 사전 자료형은 key - value 방법을 통해 저장한다.
| name | code |
| "John" | 0011 |
| "Maria" | 1234 |
* 이런 table concept을 의미하며, 정수 index가 아닌 key값을 통해서 value를 access한다.
key-valus 방식으로 저장을 하는 것으로 얻는 이점은?
A. 순서가 아닌 의미가 있는 값을 통해서 데이터 접근이 가능하다.
* 같은 말로 Hash Table이라고 불리며 데이터 관리에서 굉장히 중요한 개념이다.
* 파이썬에서 사전 자료형은 {}을 이용하여 표현하는데, 집합과의 차이점을 두기 위해 원소에 반드시 : 가 들어가야 한다.
* 사전을 표현할 때는 {key : value, key2 : value2, ... } 형태로 표현한다.
e.g. {'a' : 1, "b" : 3}
@ 사전을 만드는 방법


TIP 사전을 만들 때 key는 중복이 있으면 절대 안된다.
사전에서 key가 될 수 있는 data type은 immutable이어야 한다. (int, float, str, tuple)
@ 사전 관련 함수




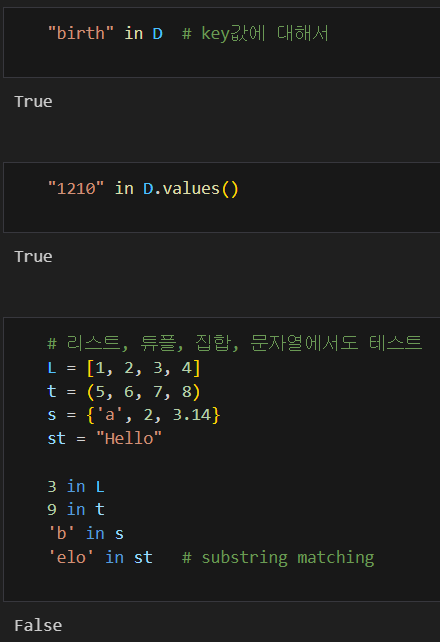
@ Sequence에 해당 데이터가 존재하는지 확인하기 : in operator
* in이라는 operator는 모든 연속형 데이터 타입에 사용할 수 있다.
* 사전의 경우에는 key값을 대상으로 하고, 리스트, 튜플, 집합, 문자열에 대해서는 해당 원소가 존재하는지 찾아서 True / False 를 알려준다.